Rows: 81
Columns: 14
$ Word <fct> almond, ant, apple, apricot, asparagus, avocado, badg…
$ Frequency <dbl> 4.204693, 5.347108, 6.304449, 3.828641, 3.663562, 3.4…
$ FamilySize <dbl> 0.0000000, 1.3862944, 1.0986123, 0.0000000, 0.0000000…
$ SynsetCount <dbl> 1.0986123, 1.0986123, 1.0986123, 1.3862944, 1.0986123…
$ Length <int> 6, 3, 5, 7, 9, 7, 6, 6, 3, 6, 3, 8, 10, 9, 8, 5, 9, 5…
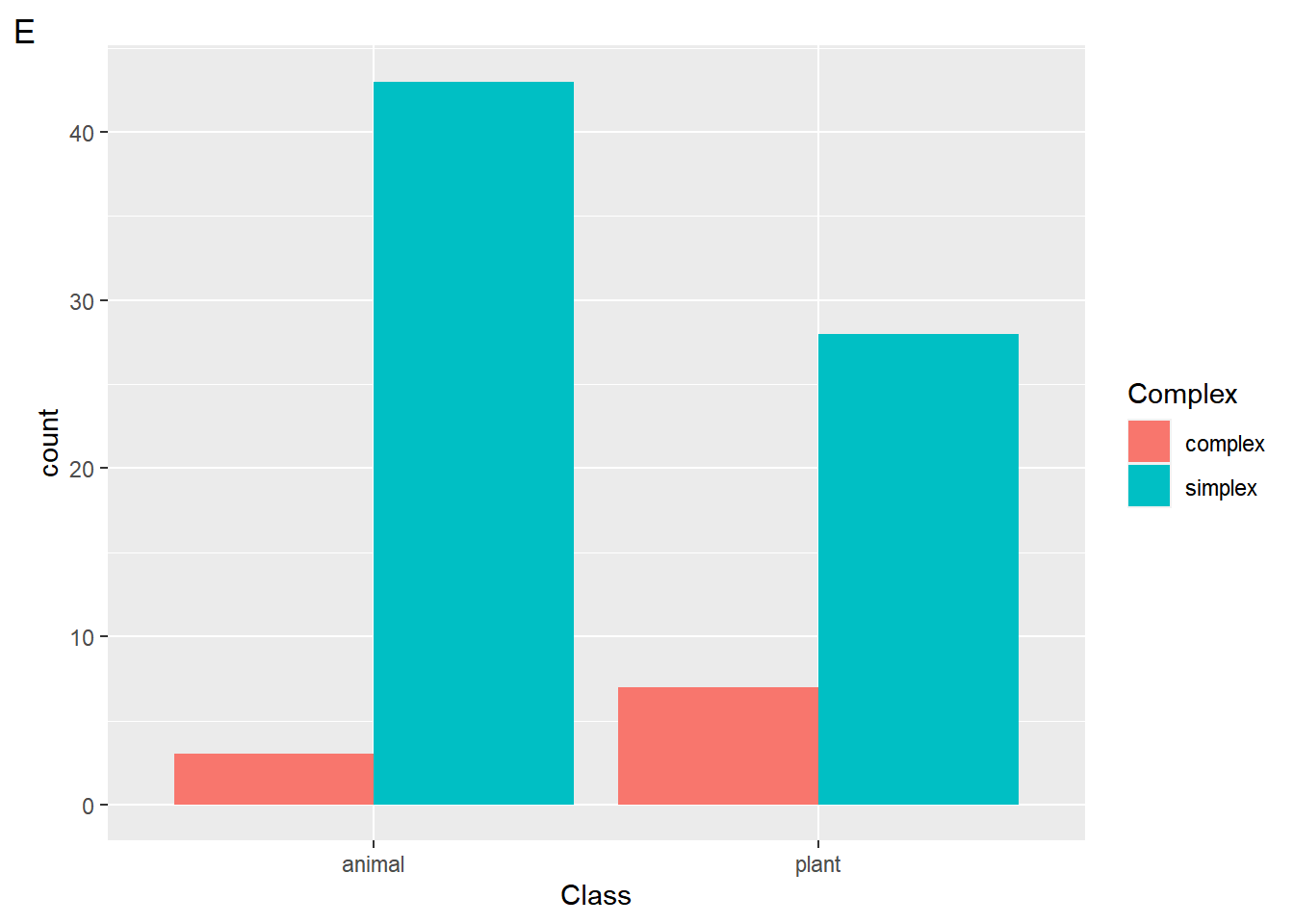
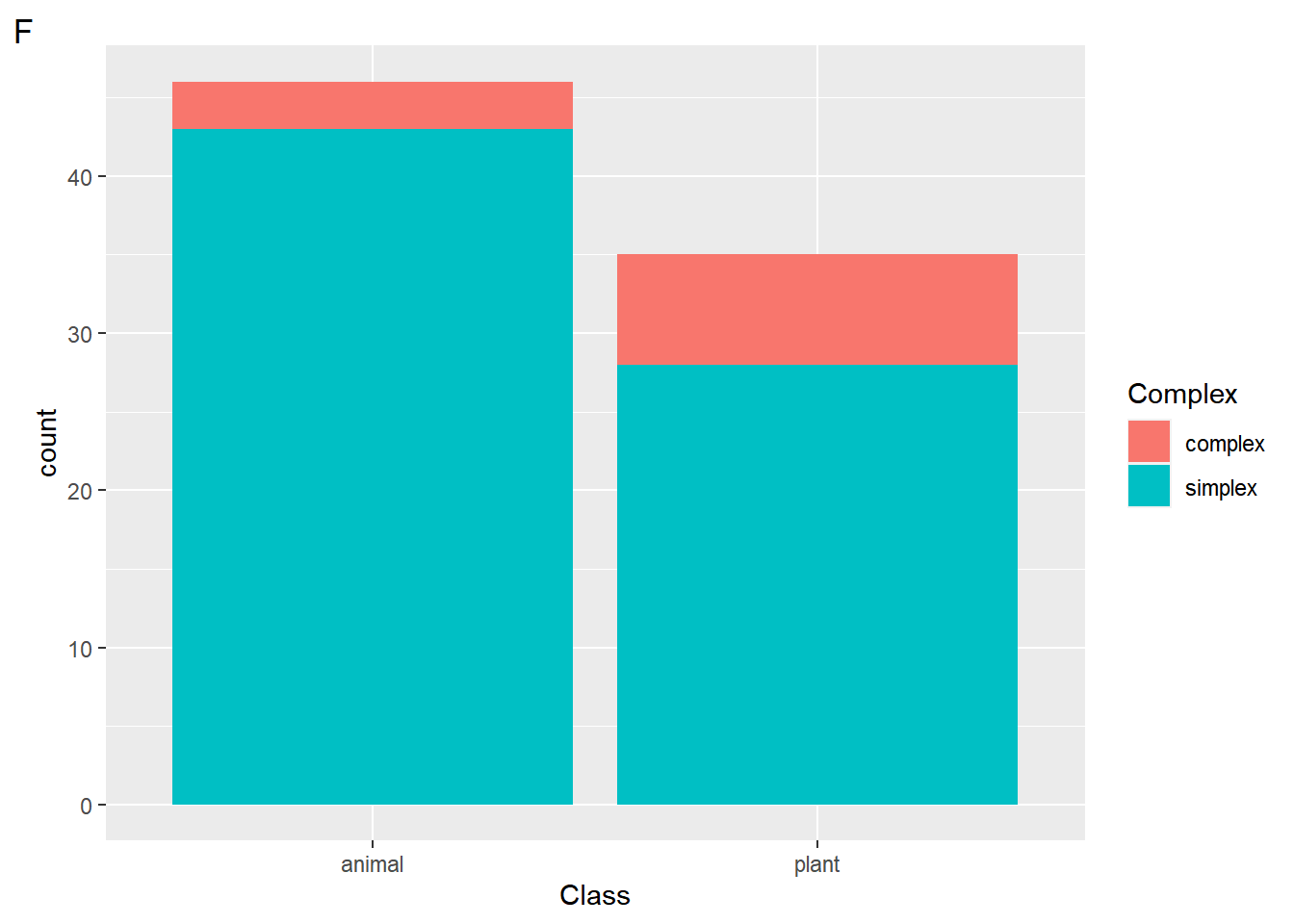
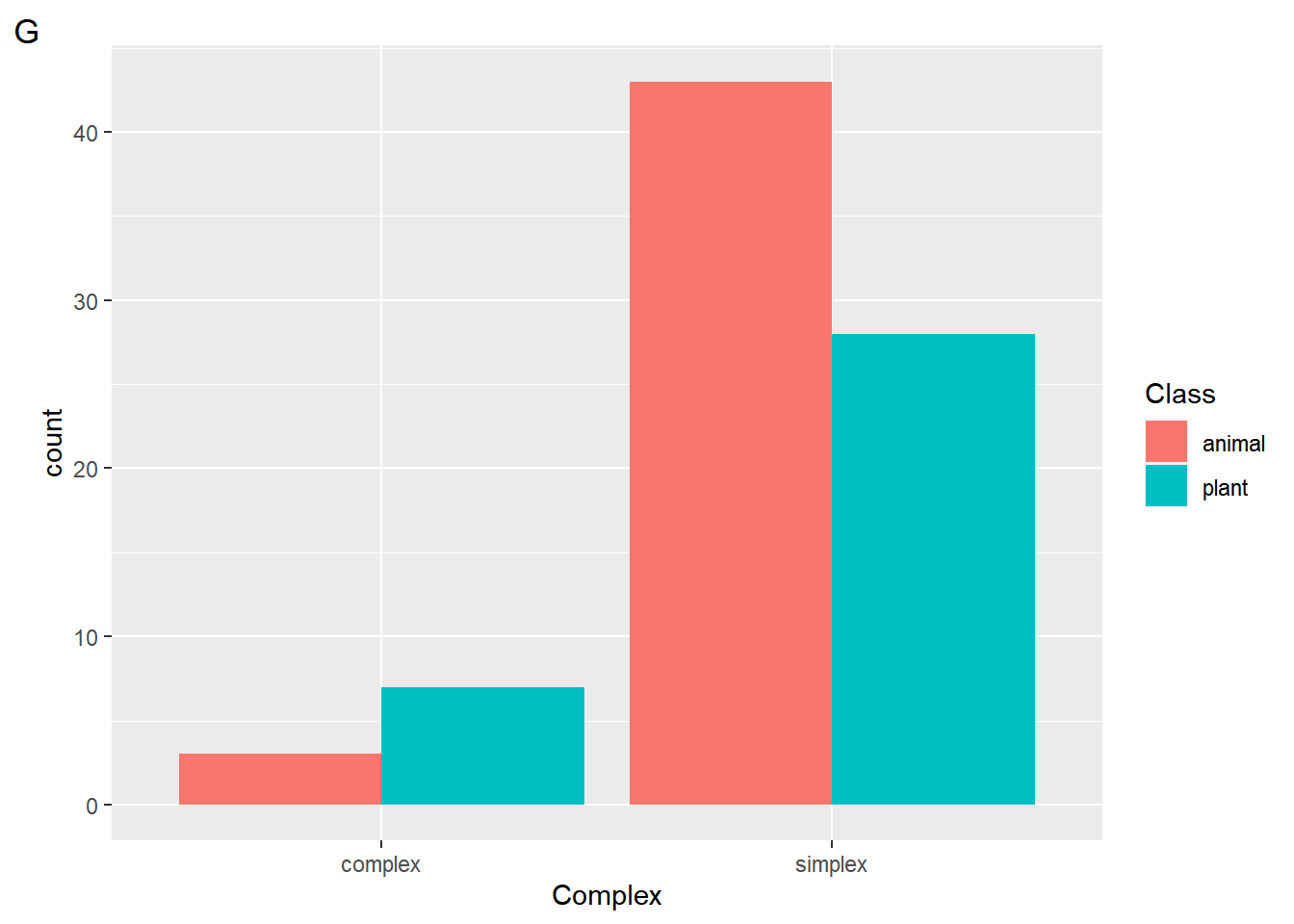
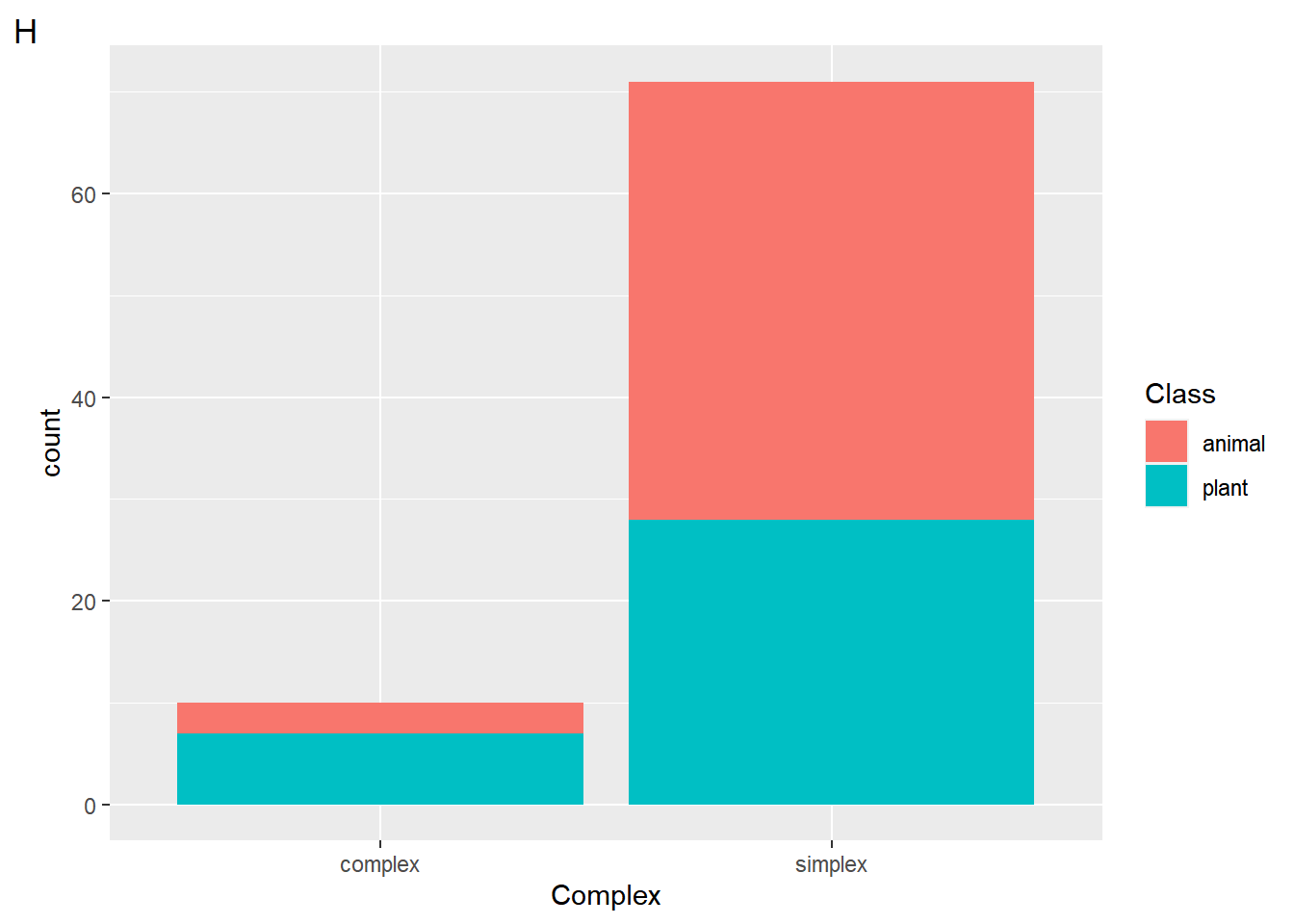
$ Class <fct> plant, animal, plant, plant, plant, plant, animal, pl…
$ FreqSingular <int> 24, 69, 315, 26, 19, 24, 53, 74, 155, 37, 118, 15, 26…
$ FreqPlural <int> 42, 140, 231, 19, 19, 6, 78, 77, 103, 14, 180, 19, 31…
$ DerivEntropy <dbl> 0.0000, 0.5620, 0.4960, 0.0000, 0.0000, 0.0000, 0.634…
$ Complex <fct> simplex, simplex, simplex, simplex, simplex, simplex,…
$ rInfl <dbl> -0.54232429, -0.70026465, 0.30900484, 0.30010459, 0.0…
$ meanWeightRating <dbl> 1.4860, 3.3489, 2.1948, 1.3216, 1.4424, 1.3256, 3.047…
$ meanSizeRating <dbl> 1.8912, 3.6275, 2.4730, 1.7597, 1.8660, 1.7737, 3.369…
$ meanFamiliarity <dbl> 3.72, 3.60, 5.84, 4.40, 3.68, 4.12, 2.12, 5.68, 3.20,…