── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.5.0 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsLab 2: Import and visualize data
Not graded, just practice
1 Tidyverse
What is the relationship between tidyverse and readr?
In the tidyverse, what does “tidy data” refer to?
What is the purpose of the purrr package?
What is the primary purpose of the readr package?
Which of the following returned this message?
2 purrr
Suppose we have the following tibble, stored with the variable df. What will map(df, mean) return?
# A tibble: 4 × 3
x y z
<int> <int> <int>
1 1 5 9
2 2 6 10
3 3 7 11
4 4 8 12Suppose we wanted to coerce each column in the previous tibble to the data type double with one line of code. Fill in the two arguments to map that would accomplish this:
- map(, )
3 Tibbles
Suppose we run the following code block. What will is.data.frame(tib) return?
tib <- tibble(x = 1:2, y = c("a", "b"))What will typeof(tib) return?
Which of the following would convert a dataframe, df, to a tibble?
Suppose we run the following code, what will is_tibble() return?
x <- tribble(
~x, ~y,
2, 3,
4, 5
)Suppose we create the following tibble, tib, what will tib$a return?
# A tibble: 4 × 3
age name alt_name
<dbl> <chr> <chr>
1 1 dory dolores
2 2 hazel <NA>
3 3 graham <NA>
4 5 joan joanie 4 readr
Many questions below refer to this dataset, borrowed from R4DS and available at the url https://pos.it/r4ds-students-csv.
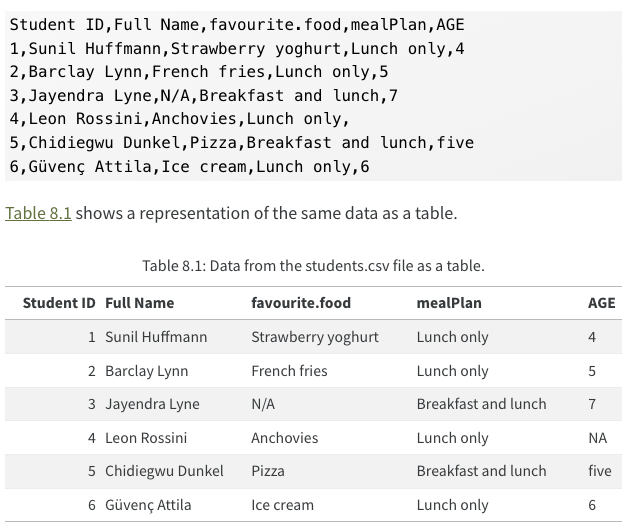
What does the csv in read_csv() stand for? Fill in the blank.
- separated values
Suppose we attempt to import the csv file given above with the code below. What will be the result?
data <- read_csv("https://pos.it/r4ds-students-csv",
col_types = list(AGE = col_double())
)Suppose we import the dataset given above and name it data. What will is.na(data[3,3]) return?
Suppose we import the dataset given above and name it data. Which of the following would return the first column?
True or false, assuming the same dataset the following code would rename the Student ID column to student_id?
data %>% rename(student_id = `Student ID`)True or false, we can use a read_*() function from readr to import a google sheet.
5 Data visualization
We will continue working with the ratings dataset from the visualization lecture (part of the languageR package). It contains the following variables:
Rows: 81
Columns: 14
$ Word <fct> almond, ant, apple, apricot, asparagus, avocado, badg…
$ Frequency <dbl> 4.204693, 5.347108, 6.304449, 3.828641, 3.663562, 3.4…
$ FamilySize <dbl> 0.0000000, 1.3862944, 1.0986123, 0.0000000, 0.0000000…
$ SynsetCount <dbl> 1.0986123, 1.0986123, 1.0986123, 1.3862944, 1.0986123…
$ Length <int> 6, 3, 5, 7, 9, 7, 6, 6, 3, 6, 3, 8, 10, 9, 8, 5, 9, 5…
$ Class <fct> plant, animal, plant, plant, plant, plant, animal, pl…
$ FreqSingular <int> 24, 69, 315, 26, 19, 24, 53, 74, 155, 37, 118, 15, 26…
$ FreqPlural <int> 42, 140, 231, 19, 19, 6, 78, 77, 103, 14, 180, 19, 31…
$ DerivEntropy <dbl> 0.0000, 0.5620, 0.4960, 0.0000, 0.0000, 0.0000, 0.634…
$ Complex <fct> simplex, simplex, simplex, simplex, simplex, simplex,…
$ rInfl <dbl> -0.54232429, -0.70026465, 0.30900484, 0.30010459, 0.0…
$ meanWeightRating <dbl> 1.4860, 3.3489, 2.1948, 1.3216, 1.4424, 1.3256, 3.047…
$ meanSizeRating <dbl> 1.8912, 3.6275, 2.4730, 1.7597, 1.8660, 1.7737, 3.369…
$ meanFamiliarity <dbl> 3.72, 3.60, 5.84, 4.40, 3.68, 4.12, 2.12, 5.68, 3.20,…Fill in the blanks below with one of the following words: data, aesthetics, geom.
The basic ggplot involves: (1) using your , (2) defining how variables are mapped to visual properties (), and (3) determining the geometrical object that a plot uses to represent data ()
When ggplot2 maps a categorical variable to an aesthetic, it automatically assigns a unique value of the aesthetic to each level of the variable. What is this process called?
The code below generated which of the following figures?
ggplot(
data = ratings,
mapping = aes(x = Frequency, y = meanFamiliarity)
) +
geom_point(mapping = aes(color = Class)) +
geom_smooth(method = "lm") +
theme_classic(base_size=20)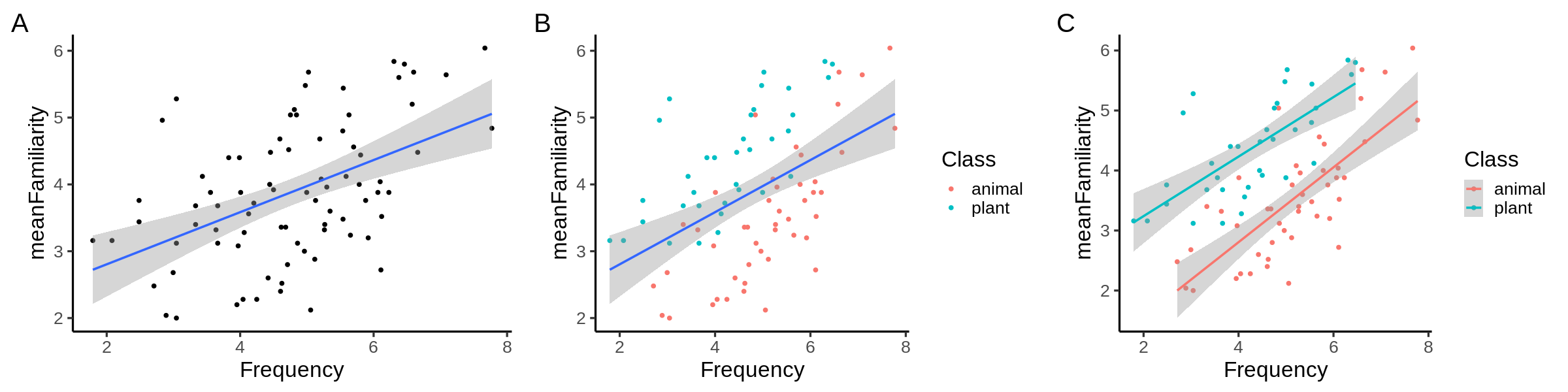
Suppose we want to map the variable Complex to the color aesthetic in a scatterplot. Which of the following arguments could we pass to geom_point()?
Which geoms are depicted in the following figure?
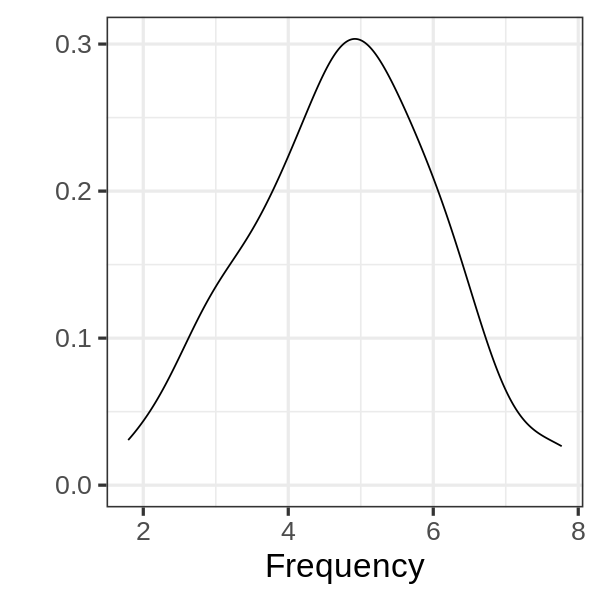
Which geoms are depicted in the following figure?