





Main
- in R:
y ~ 1 + year, in eq: \(y = w_1x_1 + w_2x_2\)

- in R:
y ~ 1 + sex, in eq: \(y = w_1x_1 + w_2x_2\)

- in R:
y ~ 1 + year, in eq: \(y = w_1x_1 + w_2x_2 + w_3x_3\)

Data Science for Studying Language and the Mind
2024-10-08

To review what we learned before break, let’s explore the relationship between Frequency and meanFamiliarity in the ratings dataset of the languageR package.
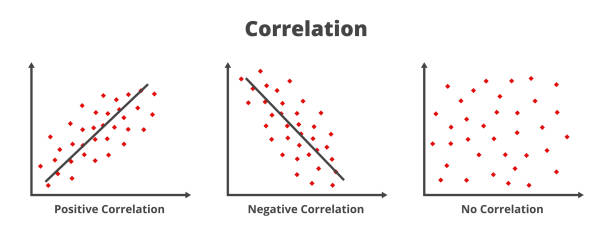
If there was no relationship, we’d say there are independent: knowing the value of one provides no information about about the other. But that’s not the case here.

In a linear relationship, when one variable goes up the other goes up (positive); or when one goes up the other goes down (negative).

One way to quantify linear relationships is with correlation (\(r\)). Correlation expresses the linear relationship as a range from -1 (perfectly negative) to 1 (perfectly positive).
Take a few minutes to try this yourself!
Use the infer way to visualize the sampling distribution and shade the confidence interval we just computed. Change the x-axis label to stat (correlation) as pictured below.

How do we test whether the correlation we observed is significantly different from zero? Hypothesis test!
Step 3: Decide whether to reject the null!
Interpret our p-value. Should we reject the null hypothesis?
Correlation is a simple case of model building, in which we use one value (\(x\)) to predict another (\(y\)).

Even more specifically — formally, the model specification — we are fitting the linear model \(y = ax+b\), where \(a\) and \(b\) are free parameters.

Correlation is the slope of the line that best predicts \(y\) from \(x\) (after z-scoring)


Take a few minutes to try this yourself!
Ask ChatGPT what type of model it is made with?


Output (y) cannot be expressed as a weighted sum of inputs(\(y=\sum_{i=1}^{n}w_ix_i\) ); pattern is better captured by more complex functions. (But often we can linearize them!)


To illustrate how this simple equation scales up to complex models, let’s start with a simple case (“toy”, “tractable”).
# A tibble: 2 × 2
x y
<dbl> <dbl>
1 1 3
2 2 5
When we have more equations than unknowns we cannot solve the system directly (we have an overdetermined system), but we can find a soulution with linear algebra.

What is the thing you are trying to understand?
What could explain the variation in your response variable?
y ~ 1, in eq: \(y=w_1x_1\)y ~ 1 + year, in eq: \(y = w_1x_1 + w_2x_2\)
y ~ 1 + sex, in eq: \(y = w_1x_1 + w_2x_2\)
y ~ 1 + year, in eq: \(y = w_1x_1 + w_2x_2 + w_3x_3\)
y ~ 1 + year + gender + year:gender
y ~ 1 + year * gendery ~ 1 + year * sex + I(year^2)
