Lab 5: Hypothesis testing
Not graded, just practice
Practice your new stats skills with these practice exam questions! Best to open a fresh Google Colab notebook and test things out! Refer to the study guide to find answers as well.
More than one answer may be correct!
If you would like to practice with a set of data, you can import the following dataset with read_csv. Note that females are coded as NA in this dataset!
# brain volumes simulated from Ritchie et al
"http://kathrynschuler.com/datasets/brain_volume.csv"1 Visualize a categorical variable
Which of the following is the best choice to visualize a categorical variable? Choose one.
Which of the following figures shows a box plot?
Rows: 5216 Columns: 2 ── Column specification ──────────────────────────────────────────────────────── Delimiter: "," chr (1): sex dbl (1): volume ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.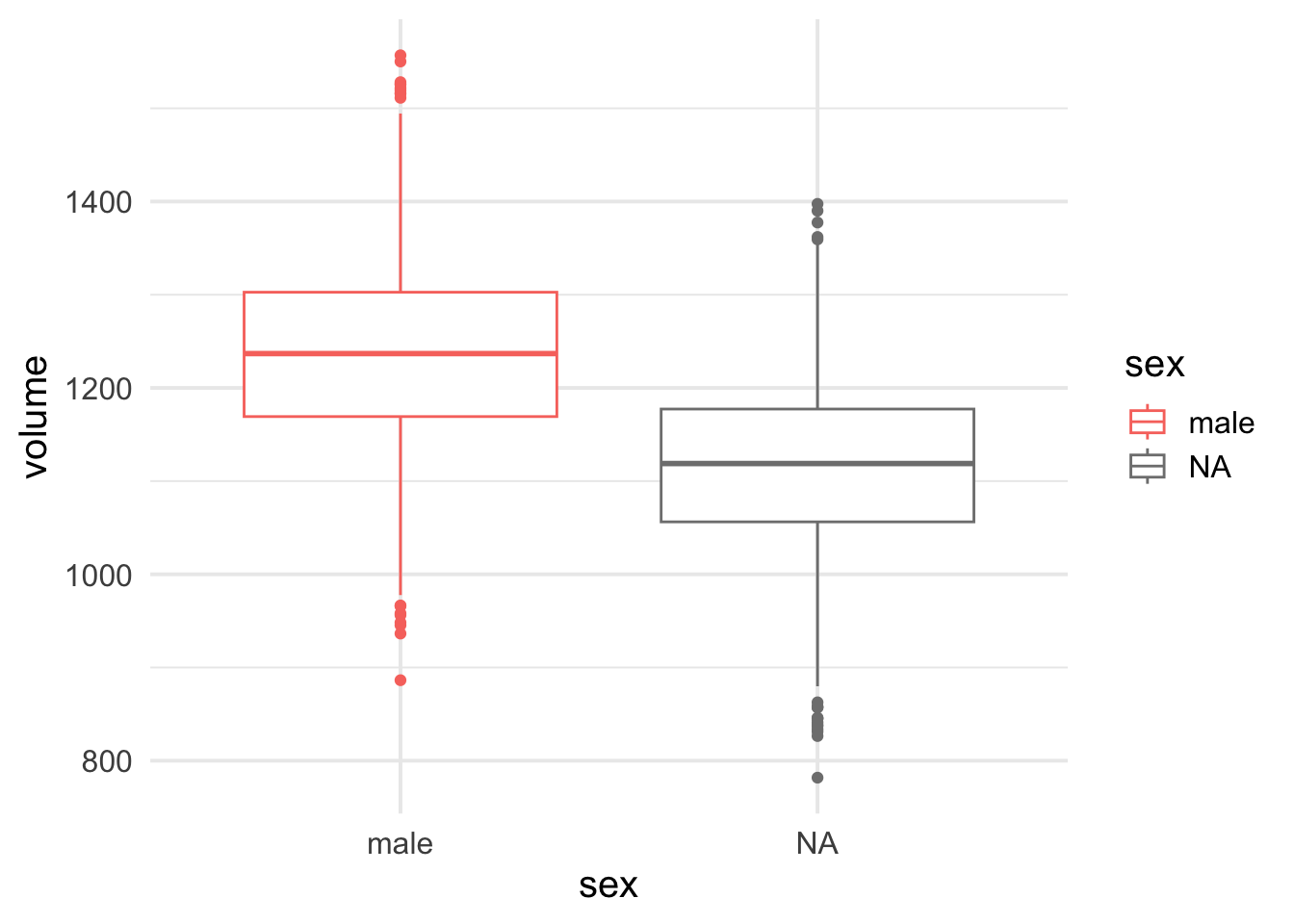
True or false, the difference in means between male and female participants in our sample is subject to sampling variability?
2 Hypothesis testing framework
Fill in the blanks about the 3-step hypothesis testing framework: (1) First we pose a , (2) then we ask if true, how likly is our observed pattern of results? This likelihood is quanitfied with a (), and (3) finally if the liklihood is leass than some thershold, we () the null hypothesis.
What is the practical reason we pose a null hypothesis?
True or false, Randomization simulates a world in which there is no relationship between brain volume and sex.
Which of the following would compute a p-value?
A large p-value means our observed value is very under the null hypothesis. A small p-value means our observed value is very under the null hypothesis.
True or false, a p-value of less than 0.05 indicates obtaining our observed value under the null is impossible
A type I error is also known as a (wrongly thinking that the effect is present); a type II error is also known as a (wrongly thikning the effect is absent)
3 There is only one test
There are two ways we can construct a sampling distribution: (1) , via brute computational force; and (2) , by assuming the data were sampled from a known probability distribution.
True or false, we can use the
t.test()function orassume(distribution = "t")with an infer object to calcuate a p-value for a t-test.
4 Correlation
We can explore the relationship between two quantities visually with a scatter plot. Which geom is best suited for this?
If there is no relationship between variables, we say they are
One way to quantify relationships is with correlation.
Correlation ranges from -1 to 1, where:
True or false, on an infer object, we can calcuate the correlation with
calcuate(stat = "correlation")Suppose we quantify how likely our observed correlation is under the null hypothesis and our p-value is 0.68. Should we reject the null hypothesis?